Radial architecture for composable commerce and modular systems

Introduction
Modern commerce systems are no longer defined by static catalogs, rigid page templates, or prewritten journeys. Instead, they’re shifting toward composable commerce, the idea that ecommerce stacks are assembled from modular, independent components rather than purchased as a single monolithic platform.
Adoption has grown steadily since the term was coined in 2020. Even organizations moving cautiously toward composable architectures now have access to production-ready AI tools that make the approach more viable. The result is a landscape where systems evolve quickly, shaped by data arriving from every direction, including real-time inventory, dynamic content models, personalization layers, and, increasingly, AI-driven behaviors that respond to what a shopper wants, or what a business needs, in the moment.
Modular composition takes the headless model a step further. Instead of relying solely on API calls for data, modules manage their own inputs and outputs, are joined by unifying hubs (e.g., a user interface), and are controlled by a CMS that describes, in data, what a given presentation should be. This creates significant flexibility, but it also introduces a new challenge where every module becomes both a point of possibility and a potential integration risk.
For teams working at enterprise scale, that risk becomes structural. Each new feature or module arrives with its own service calls, transformations, prompts, and state-management quirks. These concerns span components and product teams, often leading to overly complex integrations that are difficult to maintain.
A typical response is to wrap complexity in abstractions that present a unified API or hide distributed systems behind a single surface. Tools like MuleSoft bring external APIs together into a single interface, while design systems deliver a consistent user experience and brand identity. However, these remain independent systems. An application can access them, yet they aren’t first-class members of it.
A better approach is to view composable commerce as a truly end-to-end architecture that places the user interface and the customer-facing module at the center and connects them to the rest of the system through well-defined, AI-integrated pipelines.
In this model, the user interface serves as the hub because it is where the system becomes publicly visible as a unified whole. The UI receives well-shaped results from dedicated AI-integrated pipelines and composes them into clear, predictable views. Pipelines handle the work, domains define their structure, and the UI turns it into something a user can understand and control.
The future is an architecture for AI-integrated composable commerce, a model designed for clarity, scale, team structure, and the steady expansion of AI-driven features without overwhelming the application or its maintainers.
1. Critical mass
Modern digital systems are a result of remarkable innovation and evolution. They were built step by step, feature by feature, over time, by people solving real constraints with the tools available to them. We decoupled frontends from backends, moved content into headless CMSes, and split monoliths into services, domains, and sometimes monorepos, building APIs for everything along the way.
Design systems unified the user experience, user interface, and brand identity. Design tokens and accessibility requirements are aligned as canonical truths, providing cross-domain consistency. We turned infrastructure into code, automated deployments, decomposed interfaces into components, and integrated QA into test suites and continuous integration pipelines. Throughout the entire evolution of web system architecture, each achievement made the next one possible.
Distributed architecture was a milestone that enabled modern engineering. Built on a foundation of single-page applications, asynchronous requests to backend APIs, loose coupling of everything, and the reuse of anything possible, it was a force multiplier that helped align teams with domains and gave them autonomy free of interdependent, colocated solutions like server-side templates and client-side business logic.
Overall, distributed architecture was the right solution for multi-surface content. Design systems were a necessary contract layer that bridged design and engineering, and domain-driven design gave teams boundaries that mirrored how work actually gets done. Altogether, the advancements that by the mid-2010s matured into the modern architecture we know represent some of the most substantive achievements of web development at scale.
Yet, in many organizations today, you’ll hear a different story. Some will say that shipping is still too slow or that integrations still take too long. Scope creep is still a problem, APIs still change unexpectedly and are insufficiently documented, and releases still break unexpectedly or builds still need intervention even though the pipeline is supposedly automated.
A single feature still needs a design update, a CMS migration, backend refactoring, and a sequenced frontend integration that requires a pipeline change. It all feels fragile, requires specialized attention from people with diverse yet complementary skills, while the endless stream flows on, unabated, as day-to-day maintenance of a remarkable technology consumes time better spent elsewhere. All of the progress is real, and we should be proud that, even with all the friction and occasional frustration, the modern web works, scales, and stands as a testament to the achievement of only a short 20 or so years.
The attention and effort required to operate and maintain an enterprise system can sometimes be overstated, but the time and attention are a fact of modern technology. When distributed systems succeed, they create new kinds of work. Every decoupled module becomes another point of alignment and possible error. Every abstraction adds another surface to understand, and more underlying functionality is removed from direct influence. API schemas become dependencies, and every domain becomes a negotiation.
For the engineer, you could start your day in TypeScript. Then, before lunch, you’ve touched YAML, Terraform, Figma tokens, CMS modules, GraphQL resolvers, and, unless very lucky, Storybook configurations and maybe a GitHub Action. Ironically, this complexity comes not from failure or fragility, but from abundance.
So are we now solving the problems of complexity with more complexity? People still question things like atomic design and agile methodology, design systems still raise questions or get deprioritized, and resistance to change is natural and expected. Even if old habits die hard, AI is forcing us to ask questions we could previously ignore, and asking them opens the opportunity to simplify complex problems into easily manageable solutions, even if those solutions take focused effort to build.
If anything, the pain we feel today is evidence that our tools worked. We decomposed complexity so well that coordination became the hard part. The architecture didn’t break; it just stopped being enough. Those block diagrams of the entire system tell only a story of a system in a quiescent state. It’s only when things start moving that attention is required.
Which begs the question, if we achieved so much, why does shipping a modern experience feel harder than it should? Why are we still juggling languages to deploy a feature or writing hundreds of lines of YAML to describe a pipeline whose intent can be expressed in a single declarative sentence?
The shift begins when we let the architecture participate in the work. Distributed systems gave us boundaries, domains gave us focus, design systems gave us contracts, and pipelines gave us automation. AI gives us the ability to unify them. When these parts and pieces converge within an architecture designed for them, with AI agents as first-class participants, coordination becomes not just conversational but also structural. In other words, AI inhabits the structure, but joins the conversation on the system’s behalf.
What does that actually mean? Consider a modern CI/CD pipeline and what it takes to describe the pipeline’s intent. If using a tool like CircleCI, the YAML file for a job to checkout, lint, build, test, and deploy to production looks something like this:
version: 2.1
orbs:
node: circleci/node@5.0.1
slack: circleci/slack@4.12.5
jobs:
checkout_code:
docker:
- image: cimg/node:20.9
steps:
- checkout
- restore_cache:
keys:
- v1-npm-deps-{{ checksum "package-lock.json" }}
- v1-npm-deps-
- run:
name: Install dependencies
command: npm ci
- save_cache:
key: v1-npm-deps-{{ checksum "package-lock.json" }}
paths:
- ~/.npm
- persist_to_workspace:
root: .
paths:
- .
build:
docker:
- image: cimg/node:20.9
steps:
- attach_workspace:
at: .
- run:
name: Build application
command: npm run build
- persist_to_workspace:
root: .
paths:
- dist
- node_modules
lint:
docker:
- image: cimg/node:20.9
steps:
- attach_workspace:
at: .
- run:
name: Lint code
command: npm run lint
test:
docker:
- image: cimg/node:20.9
parallelism: 3
steps:
- attach_workspace:
at: .
- run:
name: Run tests in parallel
command: |
CIRCLE_NODE_INDEX=${CIRCLE_NODE_INDEX:-0}
npm run test -- --ci --runInBand
- store_test_results:
path: test-results
- store_artifacts:
path: coverage
deploy:
docker:
- image: cimg/base:stable
steps:
- attach_workspace:
at: .
- run:
name: Authenticate with cloud provider
command: |
echo $GCLOUD_SERVICE_KEY | base64 --decode > gcloud-key.json
gcloud auth activate-service-account --key-file=gcloud-key.json
gcloud --quiet config set project $GCLOUD_PROJECT_ID
- run:
name: Deploy to production
command: ./scripts/deploy.sh
- slack/notify:
event: pass
template: basic_success
- slack/notify:
event: fail
template: basic_fail
workflows:
version: 2
build_test_deploy:
jobs:
- checkout_code
- lint:
requires:
- checkout_code
- build:
requires:
- checkout_code
- test:
requires:
- build
- deploy:
requires:
- lint
- test
filters:
branches:
only: mainIn an AI-integrated system, it looks something like this:
You are a build agent in a CI pipeline.
Check out the repository.
Run the build.Run the tests.
If they pass, push to production.
The best part? You don’t even have to write that.
2. The concept
If some promises are made to be broken, others are made to be kept, and the ones that are kept somtimes require thought and effort. If distributed architecture kept its promise of modular composition and domain autonomy, it also never broke any promises it didn’t make. Nowhere did it say it would be easy to build or that it would require minimal care and feeding.
The cognitive leap from server-side templates in a LAMP stack application to modular composition and decoupled domains is significant and challenging. With patterns and examples, understanding is easier, but for every example we have now, there was a time when it was little more than an idea.
Often, those ideas are injected into the prevailing status quo with mixed results. Sure, they work in the small space within the scope of the experiment, but new ideas inhabiting old systems are limited in what they can do unless they replicate those systems’ patterns. This is technology’s two steps forward and one step back, which keeps it evolving even if with occasional misses.
jQuery, Backbone, Sketch, SOAP, and so many more were perfect for their time, evolutionary, and then outdated. Yet the underlying systems and their intent remained. Outdated as they may be, they were important stepping stones toward the present, and AI now challenges the present. Already, new patterns and ideas are emerging.
The first step, as many organizations are realizing, is to test new technologies within existing systems. As experiments or pilots, they’re fine, yet they often never make it to production because the system isn’t really made for them.
Instead, we can take the existing distributed architecture and reshape it for AI integration and future success by rethinking the relationships between modules and adapting how we organize them to enable AI to operate effectively within them.
3. Radial architecture
Distributed architecture gave us modularity, but it never explained how those modules relate once the system is actually in motion. What’s missing isn’t another framework, API layer, or integration surface; it’s an architectural shape that supports dynamic behavior across domains.
Modern architecture diagrams are static and aligned with whichever domain they serve. Design puts Figma in the middle, ops may put AWS in the middle, and the frontend puts the UI in the middle. In reality, these diagrams describe relationships that, when viewed over time, appear to flow linearly from design through development to QA, staging, and production.
AI isn’t bound by time or flow; it can exist anywhere in the system. The question, then, is how do we shape the relationships among domains in a system so they transcend the flow of time and remain dynamic? How can we control the convergence of domains toward a user-facing outcome using AI agents as workers and orchestrators?

Thinking about relationships as convergence rather than flow raises a more direct question, where do all domains resolve? In distributed commerce systems, everything ultimately resolves to the user-facing domain, which could be a browser UI, a mobile app, a sales kiosk, or an in-store POS system.
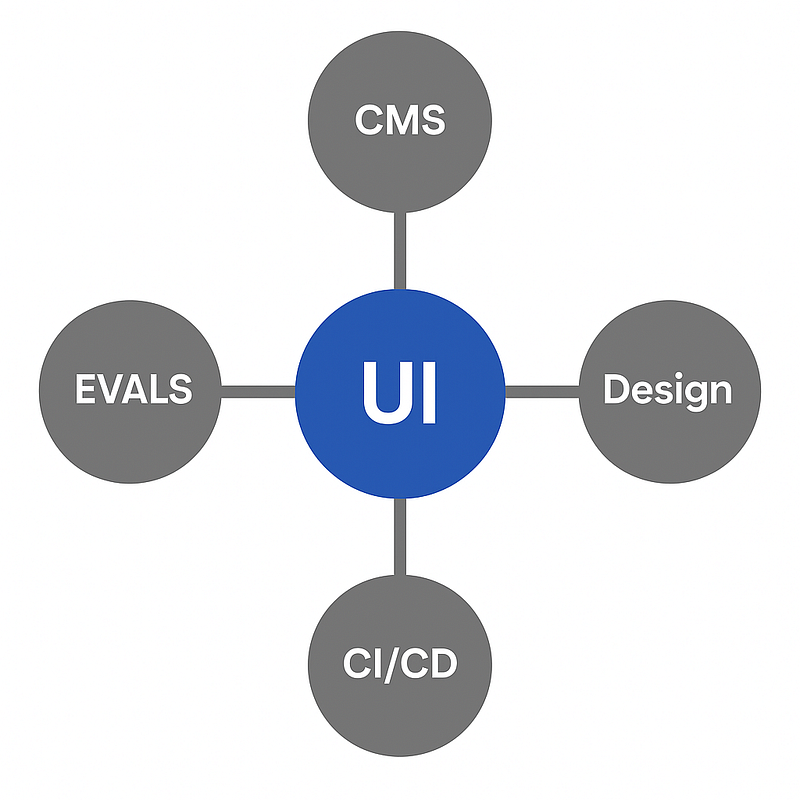
If we place the UI at the center, the domain where system outcomes resolve, it naturally becomes the hub of convergence. It becomes the center of the wheel, with other domains orbiting it and communicating through two-way pipelines and AI agents. Each domain declares its inputs and outputs as contracts, and the agent holds those contracts as canonical when aligning each spoke.
This is radial architecture, and it’s not exactly new. If we think of the UI as the hub, the nucleus of the system, we’re standing on the shoulders of patterns that have used a central coordinating domain for decades.
MVC places the controller at the center of interaction, translating intent between views and models. Primary/replica databases rely on a single authoritative primary to coordinate state across replicas. Modern distributed systems, such as clustered object request brokers (CORs), rely on a central broker to route communication among services.
Each of these patterns organizes many moving parts around a stable, opinionated center. In radial architecture, the UI takes on that central role as the system’s core domain.
4. Rethinking and reshaping
Radial architecture is about rethinking modular systems, not replacing them. It’s about consolidating and reordering existing domains so independent domains can move at their own pace and contribute their own structure. Radial architecture is as much a mindset as an implementation that reshapes how domains relate to each other, allowing AI a sure footing within each domain’s pipeline.
For years, distributed architecture assumed these domains would sort themselves out through APIs, documentation, versioning, and occasional negotiation. That approach worked when systems changed slowly or when a feature’s surface area was small enough for a handful of engineers to manage in their heads. Today, with personalization layers, real-time inventory, content variants, rules engines, recommendation systems, and now AI-driven behaviors all participating in the same experience, it is no longer enough for domains to merely expose functionality. They must expose intent, boundaries, and structure.
Arranging domains around a central hub allows for convergence before entering the build pipeline rather than within it.
Each spoke becomes a stabilizing path; an explicit agreement about how a domain contributes to the whole. It describes the inputs it accepts, the shape of the output it produces, and the rules that govern the transformation (if any) in between. As working agreements do for domain teams, exposing team inputs and outputs (if you’re familiar with Team Topologies, these are the “team APIs”), domain contracts do the same thing as data accessible to other domains and AI agents working in the pipelines between them.
When every domain publishes its contract at the edge and honors that contract every time it participates, the system gains the predictability and stability that make it robust and that AI needs for context and deterministic outcomes. If every spoke behaves consistently, the hub can rely on it without understanding each domain’s entire internal machinery. In this way, the UI does not coordinate domains so much as receive the consequences of their agreements. The wheel turns because every spoke holds its share of the load.
As AI becomes a first-class participant in these systems, the importance of these well-defined spokes increases. AI accelerates change, but that acceleration must be absorbed by an architecture capable of interpreting and composing the results. Dynamic systems require stable pathways. Radial architecture provides them, even as the work flowing through them becomes more fluid, adaptive, and intelligent.
What emerges is not a reinvention of distributed systems, but a refinement of how they converge. Domains still do their work and teams still own their boundaries, but instead of interfacing through integration patterns, they contribute through stable, structured channels. The hub waits at the center, gathering these shaped contributions and assembling them into an experience. The spokes define the work; the hub defines the outcome.
5. The hub
If the spokes define the work, the hub defines what the work becomes. In a radial architecture, the hub is not just “the frontend” or “the presentation layer.” It is the experience domain, the place where everything the system knows has to resolve into something a person can understand, trust, and act on. No matter how many services, pipelines, or agents participate behind the scenes, the only version of the system that matters to a shopper is the version they can see and touch.
That is why, even in an era where AI conversations often treat UI as a given, the interface remains the hub. Commerce cannot live entirely inside a prompt. A text field might be enough to start a conversation, but it is not enough to carry an order. Somewhere, your architecture still has to surface product details, keep a cart in sync across devices, walk a customer through checkout, support returns and exchanges, and provide a path to human or AI-powered support. The hub is where all of that has to make sense at once.
Viewed this way, the UI is not a decoration on top of the system; it is the system’s point of accountability. Radial architecture helps by giving the hub a clear contract with the rest of the system. Each spoke is responsible for delivering a well-structured contribution, such as product data optimized for a PDP, faceted results for a listing page, eligibility for a promotion, or a recommendation block tuned to a given context. The hub does not need to know how each of those results was produced; it only needs to know that when it asks, the answers arrive in a form it can compose into a coherent page or flow.
6. Pipelines and blueprints
If the hub is where everything resolves, pipelines are how everything gets there. They are the stabilizing paths between domains, the conduits each domain uses to deliver a shaped contribution the hub can trust. In a distributed system, we’re used to thinking of these conduits as integrations in which one team calls an API, transforms a payload, and passes the result to another team. Pipelines shift that thinking by turning the domain outputs into an ordered, predictable flow.
A pipeline is a dynamic flow constrained by the rules and guardrails defined in a blueprint’s contract.
Blueprints are what make this possible, and they come first. They define the shape of a domain, its inputs, its expected outputs, and the boundaries that govern its participation in the larger system. Captured as contracts, often as typed JSON, a blueprint may contain a single contract or a family of them, each describing what a domain is allowed to do, the fields a contribution must contain, the types they must conform to, the actions that are permitted, and the transitions and branches those actions may take. A blueprint isn’t concerned with how many services or AI models participate; it only describes the structure that must be honored when the work reaches the hub. One contract can support many different journeys, but each journey must respect the same guardrails.

A pipeline is one of those journeys put into motion as a dynamic flow constrained by the rules of its contract. It is a structured sequence of steps, expressed as data, drawn from what the blueprint allows, such as take this input, shape it with these rules, enrich it with these systems, and return it in a clearly defined form.
Another pipeline, built for a different chore, can choose a different route through the same contract. The critical point is not what each step does internally, but that every step and branch is declared up front and validated against the contract before it runs.
When steps are known, and their order and transitions remain within those boundaries, the system gains the determinism that a distributed architecture never offers by default. Distributed systems excel at autonomy and scale, but they do not prescribe how work should unfold across domains; timing, sequencing, and structure emerge implicitly rather than being declared.
In a distributed architecture, multiple services act independently, which is the point and intent of the architectural model. Still, it also produces incoherent or unpredictable interactions unless constrained by additional structure. This is also true for race conditions and timing variance. The moment you move outside one process, determinism is no longer guaranteed. The system, by its very nature, doesn’t declare the workflow as a structure; it’s a series of integrations.
A pipeline, an explicit workflow gated and controlled by contract, becomes a place where dynamic work produces stable results, no matter how much AI participates in the process. Blueprints stand apart from code and implementation details as agreements that give every domain a common language to express intent. They also stand apart from AI instructions and protocols, which define what an agent is and what it does, whereas blueprints describe what an agent is allowed to do. Since pipelines are built from those agreements, every spoke, i.e., content, UX, caching, adapters, etc., can participate at its own pace, yet still deliver something the hub can assemble confidently.
This is where AI finds its footing. An AI model enriching a search result or tuning a recommendation block becomes one step in a larger, predictable sequence. It operates inside a boundary where the blueprint defines what it receives and what it must return. The pipeline defines when it is invoked and what happens next. The hub doesn’t need to know which steps involved AI or how many times they ran. It only needs the shaped contribution that emerges at the end.
The pipeline then becomes the space an AI agent inhabits, the space at the edges between domains, and the system hub where the flow of work is both dynamic and deterministic, governed by the context of the blueprints.
7. Agents
If pipelines are where work gets done, and blueprints define the shape of work that can be done, then agents are the workers who do it.
Agents are already familiar in many systems and domains as role-based AI instances tasked with accomplishing something autonomously within a platform. They interact with a system through prompts, data, and tools, producing outputs that analyze, transform, or create artifacts on the system’s behalf.
On the surface, this is appealing, but in practice, it’s ambitious and risky. AI agents are, by nature, non-deterministic. Given the same input, an agent may produce different outputs, take different paths, or surface unexpected interpretations. That variability is often useful, even desirable, but without constraint, it becomes difficult to reason about reliability, safety, or repeatability.
Most agent systems counter this by narrowing the scope. Agents are assigned small, well-bounded tasks and evaluated continuously. Evaluators, often described as the unit tests of the agent world, check outputs, behaviors, or scenarios where an agent might drift outside acceptable bounds. Evals help, but they often operate after the fact, validating results rather than shaping the structure in which work occurs.
Radial architecture takes a complementary approach. Instead of relying solely on prompts and evaluations, it constrains agent activity structurally by embedding agents within pipelines governed by blueprints.
Understanding agents as workers inside a pipeline is necessary, but not sufficient. Reliable operation also depends on how those pipelines are created, validated, and advanced. That responsibility belongs to a different class of agent, the orchestrating agent.
Orchestrating agents
If pipelines represent a sequence of tasks toward a desired outcome, then orchestration is the act of deciding what those tasks are, in what order, and under what conditions they may proceed.
An orchestrating agent exists above the individual workers. Its responsibilities include constructing pipelines, validating them against domain contracts, delegating work to worker agents, and evaluating results as the pipeline progresses. Worker agents perform tasks; orchestrators decide what happens next.
After each step, the orchestrator evaluates the outcome and, guided by the blueprint’s rules, determines whether the pipeline can continue, whether corrective action is required, or whether escalation is necessary. In this model, worker agents never operate independently of structure. They act only within the bounds of a validated flow.
Blueprints play a central role here. They define the rules of a domain and the boundaries within which both the domain and its agents operate. A blueprint may include multiple domain artifacts, such as style maps in UX domains, brand or editorial constraints in content domains, validation rules in storefront domains, etc., but what is common to all is the set of contracts that define which actions are allowed and which responsibilities must be upheld.
Governing orchestration
If pipelines and contracts constrain worker agents, how is the orchestrator itself governed?
An orchestrator cannot simply be trusted to behave correctly because it is “higher level.” It requires its own form of constraint, one that enforces structure without embedding domain knowledge or side effects.
One way to do this is through a pipeline substrate, a pure, side-effect-free layer that validates orchestrator behavior and the actions that make up a pipeline. The substrate does not execute work or understand domain intent. Its role is structural governance.
If a contract specifies what is allowed to occur in a pipeline, the substrate confirms that the pipeline being constructed adheres to those rules. At a minimum, it must validate the pipeline as a whole, validate each action as it is advanced, and provide a deterministic execution plan based on the declared flow.
In this arrangement, the orchestrator is bound by the substrate’s governance, while the substrate remains ignorant of the domain itself.
Consider a simplified orchestration flow:
import { contract } from 'blueprint';
// Create an array of actions
const actions = [ ... ];
// Validate the actions against the contract
const structure = validatePipeline(actions, contract);
// Create the pipeline.
// The generatePipeline function takes the array of actions and returns a generator function.
const pipeline = generatePipeline(actions);
// Consume the pipeline
let current = pipeline.next();
while (!current.done) {
const action = current.value;
// Validate the action
const perAction = validateAction(action, contract);
if (perAction.error) {
'Use action resolution flow and escalate to human';
}
// Delegate the action
const result = await workerAgent.do(action);
// Evaluate the result
const outcome = eval(result);
if (outcome.error) {
'Use outcome resolution flow and escalate to human';
}
// Yield the next step in the pipeline
current = pipeline.next();
}Here, the orchestrator follows a governed path. Every action is declared, validated, and evaluated. Failure modes are explicit, and escalation paths are known. The pipeline advances only when allowed to do so, resulting in structured autonomy.
Agents in context
In radial architecture, agents do not replace systems, teams, or workflows. They inhabit the spaces between them. Pipelines are the environments in which agents operate, and blueprints provide the shared context that makes their behavior legible and trustworthy.
AI accelerates work, but acceleration without structure amplifies risk. By grounding agents in explicit contracts and deterministic flows, the architecture absorbs that acceleration without losing coherence. Together, they form a system in which intelligence can operate freely without surprising the user.
Further reading:
Using TypeScript generators in composable systems, a deeper explanation of generators and how they can be used to govern agents in workflows. Using TypeScript generators in composable systems
A code example of a pipeline substrate, https://github.com/tonym/stably/,
8. User experience
A core idea of radial architecture is that ecosystems, distributed systems unified through integrations, collapse into a single, coherent system at the point of experience. In a truly unified system, there are no longer discrete teams producing packaged outputs for other teams to consume. The most visible example of this shift is the user experience itself, and the notable absence of a traditional design system as a standalone artifact.
In a distributed architecture, a design system is typically delivered as a package, which is a library of components and tokens provided to development teams to ensure consistency in brand and interaction. In radial architecture, what was once a packaged system becomes a first-class domain. It is connected to the same hub as every other domain, participates in the same pipelines, and is governed by the same blueprints. This shift illustrates how AI changes the architectural landscape — not merely by accelerating work, but by unifying it.

Traditionally, UX sits at the interaction layer, with reusable components assembled into interfaces, often abstracted through design systems. The workflow usually begins in tools like Figma, where components are designed, composed into screens, and handed off to engineering for implementation. Those components are then recreated in code, with the hope that designers and engineers are working from the same mental model.
In practice, this handoff is inconsistent at best. Cross-discipline workflows introduce inconsistencies between design intent and implementation, ambiguity around component usage, and instability as systems evolve independently. Versioning and documentation attempt to close the gap, but they do so after divergence has already occurred.
Radial architecture reframes this relationship by treating UX not as an upstream artifact, but as a system domain in its own right. In Team Topologies terms, design system teams are no longer platform teams supporting others at a distance; they become stream-aligned teams responsible for producing a domain contribution that flows directly into the system.
Instead of publishing a prebuilt component library and managing it through versions and upgrades, UX outputs are connected to the hub through pipelines governed by blueprints. Components, tokens, and interaction rules become inputs to a build-time or run-time assembly process rather than static artifacts distributed downstream. Change no longer requires coordination through releases; it flows through contracts.
As agent workflows mature, the notion of “design handoff” disappears entirely. Design and engineering remain distinct crafts, but their outputs are absorbed into architecture in the same way as those of other domains. Tokens in Figma define intent just as API schemas define integration boundaries. Pipelines, guided by blueprints, align these subdomains continuously rather than episodically.
The result is a better structure. UX becomes a living domain whose outputs are shaped, validated, and assembled in real time, allowing the experience to evolve without sacrificing coherence.
So, do design systems go away? No. They change shape.
In a radial architecture, design systems evolve from packaged deliverables into active participants in the system itself. The principles, components, tokens, and accessibility standards that define a design system become operational. They move from being versioned artifacts handed downstream to becoming living inputs, governed by contracts and assembled through pipelines alongside every other domain.
Design remains a distinct craft, with its own expertise, judgment, and responsibility. What changes is where its output lives. Instead of sitting outside the system as an external dependency, it becomes part of the architecture, validated, composed, and expressed in real time as the experience takes shape.
Design systems evolve into the shape they should have had all along as members, not providers. They stop acting like OEM vendors supplying parts and start behaving like first-class domains contributing intent. The result is tighter collaboration, less drift, and a user experience that can evolve continuously without sacrificing coherence or trust.
9. Composition
On the opposite side of the distributed model is content. The words and pictures that fill the user experience by populating slots in components in a design system library. For composable commerce, however, content is not merely marketing or filler; it is the composition itself, built from product descriptions, pictures, user flows, and the written word.
Controlling a composition, such as a PDP or PLP, often means creating modules in tools like Sanity or ContentStack that mirror the user interface modules, which are built from design system components. If the UX domain feeds the hub with the parts to build the interactions, the content domain provides the composition and structure of those interactions.
Content, and its role of composition, becomes more interesting once we stop thinking of it as something that merely fills interfaces and start treating it as something that defines them.

In a distributed architecture, composition is parallel to UX. Content lives alongside the platform, in the case of composable commerce, the storefront, just as the design system does. The storefront pulls components from a design system as a packaged dependency, and pulls content and composition from a CMS through APIs and JSON. These domains evolve independently, coordinated through integration rather than structure.
Radial architecture changes that relationship. Composition is no longer parallel to UX; both domains converge at the hub. UX defines how an experience can be assembled with the components it provides, while content defines how that experience is assembled and what it expresses. Each contributes to shaping intent through contracts and pipelines, and the hub resolves those contributions into a single, accountable outcome. The interface, instead of negotiating between parallel systems, receives converging inputs via pipelines and assembles them into an experience that must make sense all at once.
This is why content models increasingly mirror interface models. A PDP module in a CMS often looks suspiciously like a PDP view in the application, where hero media, pricing blocks, feature lists, cross-sell regions, and supporting editorial all add up to an experience that is composed in code. That duplication reflects an underlying truth that composition, and therefore content, lives at the same level of abstraction as the interface itself.
In a distributed architecture, this mirroring becomes a coordination problem. Content teams model structure in one system. UX teams model the structure in a different way. Engineering reconciles the two in code. Each handoff introduces interpretation, drift, and delay. The system works, but only through constant alignment and delicate integration.
Radial architecture reframes this by treating composition as a first-class domain with its own contracts. Content arrives as a shaped contribution that declares its intent, structure, and constraints. A PDP composition describes not just what content exists, but how it may be assembled, where it may appear, and what relationships it maintains with other domains like pricing, inventory, and personalization.
Seen this way, the hub is not choosing between UX and content, nor is it asking them to coordinate with each other. It depends on neither directly; it depends on the pipelines that carry their contributions.
Each domain publishes its intent independently through its own blueprints and contracts. UX defines the interaction modules it can provide. Content defines the compositions it can assemble. Those contributions are carried forward through pipelines, but they are not expected to negotiate or adapt to each other directly.
The hub holds its own blueprints derived from design intent and compositional intent together. It knows which modules it can assemble and which compositions it will accept. When contributions from UX and content arrive, they are reconciled against those hub-level contracts. If they align, the experience resolves cleanly. If they do not, the mismatch is detected immediately and handled according to policy, then adapted, substituted, degraded, or escalated long before it reaches the user.
In this model, the hub never hopes that domains will stay in sync. It tells them how they must align, and the pipelines enforce that agreement in real time. This is what makes radial architecture self-correcting. Misalignment between domains is detected at the moment it matters, where outcomes are assembled, not buried upstream in tooling or discovered downstream by a customer. Orchestrating agents can respond according to policy by degrading gracefully, substituting alternatives, escalating for review, or halting the flow entirely.
The interface without composition is a guess. Composition without an interface is an inert structure. But neither is responsible for keeping the other in step. That responsibility belongs to the architecture itself, enforced through pipelines and resolved at the hub, where the experience is assembled centrally. Accountability is unavoidable in a way that enables AI to participate meaningfully.
10. The storefront
For online commerce, the storefront is where money is made. In composable commerce, the storefront is often a single-page application built with a modern framework, hosted in the cloud, and API-driven. Yet the choice of frontend technology, the storefront UI, seems like choosing from a menu of one item. In other words, are we giving it enough thought based on what it has to do rather than familiarity with what’s available?
Any framework, or no framework at all, will work fine as a storefront in general, but what are the specific roles the storefront plays in a particular system that influence the selection?
In radial architecture, the storefront is more than a thin rendering layer or a reflection of backend data into the DOM. It’s a place where pipelines converge, and system behavior becomes visible to a user. For those pipelines to add up to something meaningful, the storefront has to be both modular and reactive.

The hub needs an environment where composition is explicit, boundaries are enforceable, and the system’s intent can be represented in contracts rather than scattered across conventions. The more a storefront depends on loosely governed, loosely coordinated layers to resolve state, lifecycle, and integration, the more the system must rely on discipline and vigilance to maintain a coherent experience. That is a workable approach for human-driven systems, but it becomes untenable when agents are participants.
In a distributed API-driven architecture, the storefront is typically assembled from domain-appropriate parts and shipped as a precomposed artifact. Upstream choices are resolved by convention and by the surrounding ecosystem. The experience is mainly defined in code and routes, then populated with data.
In contract-driven, AI-enabled architecture, the experience is defined first as intent. The storefront is still implemented in code, yet its primary responsibility is no longer to “own” the composition. The application does not determine the outcome so much as serve as the governed place where outcomes are assembled. This is a different mindset from building a pixel-perfect application to a high-fidelity design, then shaping static content to the application structure.
The hub, the storefront, resolves the system’s intent through the declared intent of radial domains. The hub composes intent, not output, and is confined not by external artifacts, but by internal domain contracts.
How that resolution happens is a matter of implementation and may look like a traditional, cloud-hosted system with pipelines standing in for distributed packages. Content domain data is piped into the storefront during the resolution process. API requests are limited to in-session state changes, such as populating a PDP with a particular SKU after a user selects it, where the PDP itself is a pipeline-driven composition rather than an API-shaped runtime view.
It’s an easy step beyond that to customized outcomes suited to user behavior and emerging patterns. Imagine if agents were interpreting intent, still bound by contract, and surfacing not just targeted products but targeted compositions. The path to the user is resolved on the ground by the actual implementation. Still, the underlying system architecture adapts well to changing imperatives in ways API-driven systems can’t. In other words, the shape of the data from a given endpoint does not determine the user experience; it is consumed by it.
11. Case study: PDP
If all the possibilities of radial architecture inspire imagination or sound like a pipe dream, they remain grounded in the reality of modern engineering. We still need applications in the cloud; they still need remote APIs and asynchronous fetching, state management is just as important, and hydration remains the latest aspect of web applications that needs improvement.
Radial architecture is an evolution of distributed architecture, not its replacement. It replaces integrations between the outputs of systems within an ecosystem with AI pipelines that unify the system-of-systems into a single system by replacing manual coordination with contract-governed coordination. How that system communicates with the outside world still needs an AWS host and a domain-driven design.
To understand how we can build a PDP-like page with a radial architecture, let’s review how it’s built now. Design has a set of components. These components stack to form larger components using the principles of atomic design. Engineering has a component library with the same components. The engineer takes the design, builds the feature or app using a package of pre-built components that hopefully match the design, then commits it to a repo. The components are a package dependency maintained outside the app.
These are artifact-driven assemblies. I need the NPM package with the components or other parts like state management, remote fetching, etc. A simple declaration of what those parts are isn’t enough. So the fundamental constraint isn’t the non-determinism of integration, but the fact that all code has to exist at the time of integration. Therefore, the composability of a storefront involves building it with decoupled parts, yes, but not composing them via CMS output. Instead, the CMS only validates the composition where it should define it.
Establishing truth
Let’s flip the script. Instead of building a storefront application, let’s write a contract for agents to do it. It’s nothing magical, just prompt coding abstracted into system pipelines through a contract that describes what agents can do. For simplicity and focus on architecture, let’s assume agent protocols and instructions already exist.
If all spokes of radial architecture converge at the hub, then the hub is responsible for the production output, in this case, the storefront. Which means hub pipelines are allowed across domains. Spoke domains, such as content or UX, may have internal pipelines and agents, but they do not extend beyond domain boundaries.
Understanding that this is a simplified example for the demonstration of architecture, not a prescription for implementation, we can imagine a hub contract for a PDP to be a JSON object and look something like:
{
id: 'storefront.resolveExperience',
steps: [
{
id: 'preflightAlignment',
actionType: 'eval.validateAlignment'
},
{
id: 'resolvePageIntent',
actionType: 'storefront.resolveIntent'
},
{
id: 'fetchCompositionBlueprint',
actionType: 'content.pageBlueprint'
},
{
id: 'resolveUxModules',
actionType: 'ux.resolveModules'
},
{
id: 'resolveDataRequirements',
actionType: 'content.resolveData'
},
{
id: 'assembleExperience',
actionType: 'storefront.assembleExperience',
terminal: true
}
],
transitions: [
{
from: 'preflightAlignment',
to: ['resolvePageIntent']
},
{
from: 'resolvePageIntent',
to: ['fetchCompositionBlueprint']
},
{
from: 'fetchCompositionBlueprint',
to: ['resolveUxModules']
},
{
from: 'resolveUxModules',
to: ['resolveDataRequirements']
},
{
from: 'resolveDataRequirements',
to: ['assembleExperience']
}
],
structural: {
requiredSteps: [
'preflightAlignment',
'resolvePageIntent',
'fetchCompositionBlueprint',
'assembleExperience'
],
orderConstraints: [
{
before: 'resolvePageIntent',
after: 'preflightAlignment'
},
{
before: 'assembleExperience',
after: 'preflightAlignment'
}
],
allowDynamicInsertion: true
}
}These are the actions an orchestrator can use to create a pipeline and iterate through it. Depending on the implementation or the substrate in use, the shape may change, but the intent remains. Declare the allowed actions and their dependencies in a way that an impartial authority can validate.
The key to the contract is not only available actions, but where those actions lead. content.pageBlueprint could mean an agent connects to the content domain and requests a blueprint for a specific page, a PDP in this case, and returns it to the orchestrator. We know this action exists because the content domain has published it as a domain contract.
content.pageBlueprint
Unlike the hub domain, however, a spoke domain’s contract resembles a menu of responsibilities the domain fulfills, which agents can request without accessing the domain itself. Is the spoke domain contract an API? Think of it as an API schema, but also as tools.
Back in the hub, an orchestrator is prompted to build a PDP and generates a pipeline using the contract. The orchestrator then validates the pipeline, turns it into a proper form, such as a generator, and steps through the sequence of actions.
When the content.pageBlueprint action is delegated to a worker agent, it could look like:
{ type: 'content.pageBlueprint', payload: { page: 'PDP' } }The worker agent retrieves the PDP blueprint from the content domain (in this case, Sanity) and returns it to the orchestrator.
{
"_type": "page",
"pageType": "PDP",
"title": "Default Product Detail Page",
"modules": [
{
"_type": "productGallery",
"slot": "product.media",
"markers": {
"images": "product.images"
}
},
{
"_type": "productSummary",
"slot": "product.summary",
"markers": {
"title": "product.title",
"price": "product.price",
"rating": "product.rating",
"shortDescription": "product.summary"
}
},
{
"_type": "productOptions",
"slot": "product.options",
"drivenBy": {
"taxonomy": "product.category"
},
"markers": {
"options": "product.options"
}
},
{
"_type": "addToCart",
"slot": "purchase.action",
"markers": {
"sku": "product.sku",
"availability": "inventory.status"
}
},
{
"_type": "accordionGroup",
"slot": "product.details",
"items": [
{
"label": "Details",
"marker": "product.details"
},
{
"label": "Fit & Care",
"marker": "product.care"
},
{
"label": "Shipping & Returns",
"marker": "commerce.shippingPolicy"
}
]
}
]
}The orchestrator now knows which modules are required to compose the PDP, where data comes from, and how to place it in the page components.
Further actions will get those modules from the UX domain, which may be distributed as traditional packages, generated at build time from a contract, or a combination of both. The point is, they are available in some form, even if the hub domain has to generate them from component blueprints.
Build time composition
What’s really happening in a CMS-driven storefront today is that composition logic lives in runtime code. A page renderer fetches a CMS document, walks its module list, and runs it through a component registry, often a switch statement, a mapping table, or a dynamic import layer that decides which UI artifacts to load based on _type, taxonomy, and a growing set of edge cases. That “page factory” works, but it’s expensive. It adds runtime overhead and concentrates architectural complexity within the app, where every new module, variation, or exception becomes another conditional branch to maintain.
Radial architecture moves that factory out of runtime and into a contract-governed pipeline. Instead of fetching the composition at request time and assembling the experience on the fly, the orchestrator resolves the blueprint, verifies alignment, resolves the required modules and data markers, and delegates assembly to a worker agent before the experience is served. The storefront still looks like a normal app in the cloud, but it no longer has to anticipate how to compose a page. The page is built to the blueprint ahead of time, validated against declared contracts, and deployed as an artifact that the runtime can serve directly.
The only thing left for the runtime to do is fetch the product data and populate the page.
12. Evals and testing
We think of evals as tests for agents, and they are. Like unit tests, they test small parts of the system, ensuring predictability and consistent AI outcomes.
While this is important within a domain and across pipelines, how is the system itself tested? For system testing, there is an eval domain, similar in role to QA, but with radial architecture, eval testing happens before build time, not after.
One of the core principles of radial architecture is the asynchronous autonomy of system domains. Each domain progresses, evolves, and flows at its own pace. This inevitably leads to misalignment, either intentionally or not.
Looking at the PDP example and the storefront contract, you’ll notice an action, eval.validateAlignment that must come first in any pipeline. This is a pre-flight action to use tools in the eval domain to assess domain alignment across the system.
eval.validateAlignment
Validating alignment is one way to make sure domain contracts can support each other. If content specifies a page composition, UX should be able to support it with the required modules. If the content specifies a marketing banner at the top of the PDP but that module is not yet available, the eval agent will notice and record it as a system mismatch.
The intentional mismatch comes from anticipating the new module, accounting for it, and letting the system handle its availability. It’s not a blocker, but the hub orchestrating agent needs to know about the mismatch to adapt the output by either omitting the marketing banner or leaving a placeholder in the code. Rules for handling discrepancies, such as a missing module, could be provided in the orchestrator protocols or instructions, or in the hub blueprint.
The eval domain, like the hub, is a domain allowed to build cross-domain pipelines, but with the purpose of assurance, not execution. Eval domains use the same pipeline substrate, but their pipelines inspect rather than build.
Eval domain output is an assessment, more than a pass/fail grade, but not a prescription or remedy. It’s simply a report on the system’s health and the things to look out for. It could also be a diagnosis of system failure, or possible failure if mismatches cannot be resolved by contract. In this sense, eval is the system watchdog, similar to services like DataDog, that keep an eye on things and raise alerts if required.
The eval domain can also serve the traditional responsibilities of QA. If alignment is assessed before a build, output could be tested in similar ways with AI worker agents replacing e2e tests or traditional QA tools. Where those boundaries lie is a matter of implementation, meaning that the eval domain has no predefined prescriptive boundaries. It serves the purpose of all testing by providing enough to satisfy confidence in the system, but the system’s purpose and shape determine how that confidence is achieved.
13. Case study: PLP
The PLP is one of those deceptively complex pages that implementers sometimes underestimate. On the surface, it’s a filtered list of products. In reality, it’s a web of state management rules and intertwined reactions to changes.
Most PLPs contain the same things in one form or another. There’s a list of products with details for each, a panel of sorting and filtering facets, a search bar, and a shopping cart of some kind.

The difficulty isn’t so much about the composition; a PLP uses a content blueprint fetched from Sanity or the content domain platform of choice, and it uses the same UX components, or a subset of them, as any other page. The difficulty is showing the right products, keeping track of the filter settings, and grouping everything in pages. Additionally, PLP pages often require multiple asynchronous requests to product database APIs to update the list while the user refines the facets.
If radial architecture gets you into production cleanly, traditional APIs keep you there. If the PDP is about a page that can display any SKU based on taxonomy and product data, the PLP is about multiple SKUs based on user-defined criteria. That makes the PLP about state, not layout, intending to define its shape earlier.
Traditionally, state is primed with an initialState object, or equivalent, that declares the shape of a store, supplies default values, and bootstraps runtime memory. In radial architecture, that information is lifted out of the runtime and promoted to a domain contract that the agents use to generate targeted state slices, or whatever the platform solution requires.
initialState
Let’s look at another PLP example.

In this case, we see the same basic layout with the same modules, a facet panel and a product list. Except now those modules are contained in a host application.
The host application is the application shell that provides scaffolding, global features, and functionalities. The host application provides the header and footer, the branding and navigation, the shopping cart, and anything else used on every page. It also provides the store.
Each module is composed by agents using a blueprint from Sanity or the like, components from UX, and product data from external sources. The modules are opaque to each other, reacting to changes via communication with the host application store. If a facet changes, the host app store is notified, handles the change, then passes the updates to the modules.
How this actually works is an implementation detail, and could be NGRX observables, Redux Toolkit actions, Zustand hooks, etc. The point is, state is global, and drives everything down the module chain without modules having to know anything about each other.
This is composition gold and very AI-friendly when the shape of state is a contractual boundary, defined by intent, not the shape of the data from the source. This still means side effects may be necessary, but they, too, are owned by the host application. In a way, state makes the storefront its own radial architecture with modules converging on the host application as a hub. If system architecture resolves system intent at the hub domain, the runtime storefront resolves user intent at the host application hub. Like system domains, page modules remain autonomous.
A natural benefit beyond efficient state management is compositional freedom. PLPs may have mostly the same features, but different markets will arrange them differently.

Other markets may need a unified look across brand families or regional outlets. Radial architecture provides an opportunity for this without runtime branching or dynamic theming by knowing the target brand at build time.

Neither does the PLP have to be consumer-facing. In B2B applications, PLPs are much more data-rich and dense. They are also more static, meaning product lines are relatively stable in more situations than fast-moving consumer verticals.
If that’s the case, or even if it isn’t, can it pre-populate a product category? Yes. A domain not mentioned is an optional adapters domain, which handles system communication with the outside world.
Not every system needs an adapters domain, but if your initial PLP is a list of men’s wallets, actions could be built into a pipeline to use an adapter to fetch product data at build time and have the category PLP ready to go without runtime edge functions to do the same thing.
For data-heavy B2B PLPs, this could be a client-side performance optimization. The best part is that all of this, composition, theming, state, etc., happens before the assembled application enters the CI/CD pipeline.
14. Environments and CI/CD
One of the easiest misunderstandings of radial architecture is to mistake its pipelines as a replacement for CI/CD. While a reasonable concern, the opposite is true. CI/CD does not go away.
CI/CD pipelines are responsible for environments and deployment to those environments. Production, staging, testing, etc., are pipeline targets, often prepared or validated as part of the CI/CD workflow. The promotion and deployment lifecycle of a storefront application remains unchanged. What changes is what enters that lifecycle, and how much intent has already been resolved before it does.
In a distributed architecture, CI/CD is often asked to do too much. Pipelines, in addition to building and deploying code, include orchestration logic, environment-specific behavior, and assumptions about how the system’s components fit together. YAML becomes the place where intent goes to hide. As systems grow, the CI pipeline quietly accumulates responsibility for coordination that belongs elsewhere.
Radial architecture patterns, the blueprints, pipelines, agents, orchestration, evals, etc., happen before the application enters CI/CD. By the time the storefront reaches CI, it should already be a resolved artifact.
What enters CI/CD
In a radial system, the hub’s output is a prepared application. Composition has already been resolved against content blueprints, UX modules have already been selected, aligned, or substituted, and known mismatches have already been evaluated and handled according to policy. The experience’s structure has already been validated against contracts.
From the CI pipeline’s perspective, nothing about this looks exotic. It receives a repository or a build artifact, runs its checks, and promotes it through environments. The difference is that CI is no longer responsible for figuring out what the system is supposed to be. It is responsible only for shipping what the system has already decided to become.
Placing agents in the CI pipeline is an upgrade, but the pipeline chores are the same. The same AI patterns in radial pipelines also apply to CI pipelines, enabling the reduction of rule-based YAML to instruction- and contract-based prompts.
Local development
Local development benefits from the same separation. In a traditional composable system, developers often need to run partial systems, mock CMS responses, stub APIs, and mentally simulate how composition will behave at runtime. Much of this work exists to compensate for the fact that composition is deferred until the application is already running.
In a radial architecture, local development starts with resolved intent. A developer can work against a known composition blueprint. The page structure is already assembled, and the module boundaries are already enforced. The contracts that shaped the experience are visible and inspectable.
Local development becomes about iterating on behavior and presentation within a resolved structure, rather than debugging the mechanics of assembly. When something changes upstream, such as content structure, UX capability, or domain availability, it enters the developer workflow as a contract change, not a runtime surprise.
Promotion and environments
Because intent is resolved ahead of CI/CD, environment promotion becomes simpler. Gone is the need to maintain parallel composition logic across staging and production. There is no need for environment-specific conditionals to decide how a page should assemble itself or for runtime feature flags to hide or test unresolved decisions.
If the system cannot be assembled coherently, it should fail before promotion in a way visible to the orchestrator, recorded by evals, and surfaced as a structural issue, not discovered in a CI/CD pipeline or after deployment to users.
CI/CD remains the gatekeeper of quality and stability, but it is no longer the place where architectural uncertainty accumulates. Radial pipelines resolve what the system is, and CI/CD determines whether it is ready to ship. Keeping those responsibilities distinct is what allows AI to participate meaningfully without turning the delivery process into an opaque experiment.
15. Beyond the repo
How do agents communicate with domains? So far, we’ve seen how pipelines can bridge domains and have generally assumed the presence of some API. In reality, this is true; however, there are better tools for domain access.
Many platforms and services provide MCP servers, and in radial architecture, they can be helpful for pipeline agents calling spoke domains. Sanity, Contentful, and many other CMSes now have official MCP servers that allow access to data and projects. In UX domains, third-party component libraries like ShadCN provide MCP servers to access their libraries. Custom MCP servers can be built at the edge of every domain, or as an abstraction for traditional APIs.
When using MCP servers, spoke domain contracts often map to MCP tools that allow an agent to request data from a domain without accessing it directly. For the PDP or PLP build flow, an agent can call the content domain MCP server for the page blueprint, then call the UX domain MCP server for the components. MCP servers could be used at the hub to allow agents to provide data, and an eval agent can use domain MCP servers to run validation and alignment assessments.
For traditional APIs, an adapter domain could provide MCP tools to access external APIs. Those APIs still matter at runtime, and although domains have MCP servers for agents in pipelines, domain APIs, such as CMS APIs, remain for runtime asynchronous calls.
Additionally, for external services that have MCP servers, there are a growing number of MCP gateways like Smithery and Composio that allow access to a registry of MCP servers or that allow you to create or configure MCP access to services that don’t provide official MCP servers.
Localization
Localization is often treated as a late-stage concern in modern systems. Strings are externalized, translation files are generated, and region-specific overrides are layered on top of an experience that was already designed, built, and composed. This approach works well enough for static interfaces, but it starts breaking down as soon as localization affects structure, behavior, or meaning beyond language.
Radial architecture treats localization differently. Instead of embedding localization logic throughout the system, it elevates localization to a first-class domain that participates in the same contract-governed pipelines as content, UX, and other spoke domains.
A localization domain publishes blueprints that describe what it can provide, such as translated strings, regional formatting rules, legal requirements, cultural constraints, and, in some cases, structural variants. These contracts are consumed by pipelines just like any other domain contribution. An agent does not switch locales at runtime; it requests a localized contribution that already conforms to the system’s expectations.
This distinction matters because language is rarely the only variable that changes across regions. Currency formatting, tax presentation, measurement units, shipping rules, legal disclosures, and even the prominence or placement of UI elements can vary by market. Treating localization as a domain allows these differences to be expressed structurally rather than applied as conditional patches.

In a radial system, localization converges at the hub alongside other domains. A pipeline resolving a PDP or PLP may include steps such as resolving a localized composition blueprint, selecting region-appropriate UX modules, or validating that required legal content is present for a given market. These steps are declared explicitly in the blueprint and validated before the experience is assembled.
This does not eliminate runtime localization. Some aspects of localization remain inherently dynamic, such as user-selected language preferences or session-specific formatting. Traditional APIs and client-side logic still play a role here. What changes is the balance of responsibility. Structural localization decisions move out of runtime code and into contract-governed orchestration, leaving the runtime application to handle only what truly must vary per session.
Neither does a localization domain absolve other domains from their localization responsibilities. The UX domain still owns the implementation of features such as writing direction, script, locale group, etc., while content remains responsible for the language and words. The localization domain owns the market-level rules for every locale, such as language variants and fallbacks, writing direction, number/date/currency conventions, legal and registry requirements, cultural constraints, and structural variants, if allowed.
Consider a scenario where marketing plans a sale. Content wants a promotional banner on the landing page, UX has the available modules, and localization forbids it in markets X and Y. The pipeline resolves a compliant composition for each market before deployment.
It can work the other way, too. Instead of restricting for regional compliance, localization can provide rules for opportunities in locales, such as regional holidays or events, and for targeted content shaped for global holidays or occasions, as well as access to resellers or retailers local to a specific region or market. Across large-scale systems, localization can provide tools specific to those regions and metrics from other regions.
Seen this way, localization becomes less about translation files and more about intent alignment. A localized experience is not a single application with switches; it is a family of resolved outcomes, each assembled according to the same architectural rules but shaped by different domain contributions. Now, localization absorbs rules for reporting and metrics as well as commerce.
Accessibility
Accessibility is often framed as a set of requirements to be satisfied at the edges of a system. Teams audit components, add ARIA attributes, improve color contrast, and fix keyboard navigation issues late in the development cycle. These efforts are necessary, but they are rarely sufficient. Accessibility breaks down not because teams do not care, but because responsibility for it is diffuse, reactive, and embedded too deeply in implementation details.
Radial architecture treats accessibility as a first-class concern by making it structural rather than a corrective measure. Instead of relying on downstream audits and retrofits, accessibility becomes a domain that participates in the same contract-governed pipelines as UX, content, localization, etc.

An accessibility domain publishes contracts that describe what an accessible contribution must uphold. These may include interaction guarantees (keyboard navigability, focus order, motion constraints), semantic requirements (roles, labels, landmarks), contrast and readability thresholds, and behavioral rules for dynamic content. Like other domains, accessibility does not dictate how components are implemented internally; it defines what must be true when an experience resolves at the hub.
This distinction matters. Accessibility emerges from composition, state changes, timing, and interaction between domains. A perfectly accessible button can become inaccessible when placed in an unexpected focus order, when its label is replaced dynamically by content, or when its state is driven by asynchronous behavior without proper announcements. Treating accessibility as a domain allows these interactions to be evaluated structurally rather than discovered incidentally.
In a radial system, accessibility converges at the hub alongside UX and content as a compliance framework that must pass the same eval assessments as all other domains. Pipelines resolving a page or flow may include steps that validate focus order across composed modules, ensure required landmarks are present, confirm that dynamic updates are announced appropriately, or verify that motion and animation respect user preferences. These checks occur before deployment, not after a user encounters a problem.
This does not eliminate the responsibility of other domains. The UX domain still owns the implementation of accessible components and interaction patterns. Content remains responsible for meaningful language, heading structure, and alternative text. Localization affects accessibility through language complexity and script direction. The accessibility domain coordinates and guides them, enabling validation of the final hub assembly.
One of the most important shifts is that accessibility moves out of “best effort” territory. When accessibility requirements are encoded as contracts and enforced through pipelines, they become non-negotiable, just as data shape or API compatibility is. If a composed experience violates an accessibility rule, it fails structurally, not morally. The system can degrade gracefully, substitute compliant modules, or halt promotion in accordance with policy, but it cannot quietly ship an inaccessible outcome.
Seen this way, accessibility is not a compliance tax or a late-stage concern. It is a quality of intent. A system that cannot express accessibility constraints structurally cannot consistently guarantee them, especially as AI-generated behavior, dynamic composition, and personalization increase variability.
Scaling
Scaling is often discussed in terms of traffic, throughput, or infrastructure. While those concerns matter, they are rarely the first limits organizations hit as systems grow. More often, scaling fails at the coordination level. As domains multiply, markets diverge, and product lines expand, the difficulty is no longer serving more users, but keeping outcomes coherent across a growing family of systems.
Radial architecture approaches scaling by preserving convergence while allowing proliferation. Domains are allowed to multiply, specialize, and evolve independently, but they do so through contracts that keep their contributions legible to the hub. Scaling does not mean adding more spokes indiscriminately; it means adding spokes that honor the same structural agreements.
One of the most common scaling challenges is the emergence of system families. A single platform may support multiple brands, regions, or business units, each with its own identity, constraints, and priorities. In traditional architectures, this often leads to forks, duplicated codebases, conditional logic layered into runtime systems, or sprawling configuration matrices that are difficult to govern.
In a radial system, families are expressed structurally rather than procedurally. Shared domains publish baseline contracts that define what is common across the system family. Brand- or region-specific domains extend those contracts within allowed boundaries, contributing additional rules, modules, or constraints without rewriting the system’s core logic. The hub resolves these contributions based on their declared intent rather than branching code paths.
For example, a global commerce platform may share core domains for product data, pricing, inventory, and checkout. Individual brands may contribute their own UX capabilities, content composition rules, or localization constraints. Regions may impose regulatory requirements, currency rules, or market-specific structural variants. Each of these is expressed as a domain contribution, validated through pipelines, and resolved at the hub into a concrete outcome for a given brand and market.
Crucially, scaling does not require every system in the family to converge on a single implementation. What must converge is the shape of intent. Pipelines and blueprints ensure that even when different systems evolve at different speeds, their contributions remain compatible. A brand can introduce a new experience pattern without forcing all other brands to adopt it. A region can enforce stricter compliance rules without fragmenting the system as a whole.
At this point, distributed systems could make sense. Instead of extending domains into a region or brand, an org could consider independent radial systems in each region or brand, with a hub system at corporate HQ that holds the rules, patterns, and structure for all systems in the family. When each system provides an MCP server, systems can then coordinate and operate within the core organizational rules.
Scaling a radial system, then, is less about making the hub bigger and more about keeping the spokes honest to the point that a hub system is established and regional or brand systems become spokes of their own. An extensive system is not one with many services; it’s one with many intentions. Radial architecture scales by giving those intentions a place to converge, at any level, without requiring them to become the same.
16. Governance
In distributed architectures, governance often emerges as an external influence. Teams rely on documentation, versioning discipline, and social contracts to keep systems aligned. When those fail, governance arrives as review boards, approval gates, and escalation paths layered on top of an architecture that was never designed to enforce structural alignment.
Radial architecture shifts governance from process to structure. Because domains participate through contracts and pipelines rather than informal integrations, governance becomes a question of what is allowed to converge, where it converges, and how divergence is handled. These rules are no longer buried in tribal knowledge or CI YAML; instead, they are expressed directly in blueprints, validated by substrates, and observed by evals.
Who owns the hub?
In an enterprise commerce system, the hub is typically the storefront. Revenue, conversion, trust, accessibility, and brand all resolve there. When something breaks, the storefront is where it becomes visible first. That does not imply frontend teams suddenly own everything.
Owning the hub means owning resolution, not production. The hub defines how contributions, both within the hub domain and from spoke domains, must arrive to become an experience. In large organizations, the hub may be entrusted to a core team, where other domain teams still tend to features and sprint tickets within domain boundaries, as is already a common practice.
In other verticals, however, the hub may be different. A CDN or image optimization platform may place the delivery edge at the center. An observability platform may treat evals and telemetry as the hub. A logistics or fulfillment system may converge on a warehouse or routing engine. Radial architecture does not prescribe the hub; it reveals it based on where outcomes resolve.
Domain autonomy, preserved
A common fear of centralized models is loss of autonomy. Radial architecture avoids this by making autonomy explicit rather than implicit. Domains remain free to evolve internally, content teams can restructure taxonomies, and UX teams can redesign components. None of these changes requires synchronized releases across the organization.
What must remain stable are the blueprints each domain publishes. Blueprints and their contracts are the public promises domains make to the rest of the system. They define which actions are available, which shapes are returned, and which constraints must be honored, contributing to governance by declaration.
If a domain breaks its contract, the system does not fail silently. Pipelines fail validation and evals surface misalignment. Governance becomes observable behavior when orchestrators adapt, degrade, or escalate in accordance with policy.
Drift is expected
One of the most critical governance shifts in radial architecture is how it treats drift. In traditional systems, drift manifests as broken builds, runtime errors, or misaligned releases. Teams scramble to restore alignment after damage has already occurred.
Radial architecture treats drift as both inevitable and manageable. Because domains move at different speeds, intentional misalignment is often desirable. A content team may plan for a new module before UX delivers it; UX may ship a component before content adopts it; or pricing rules may change before presentation logic.
System evals exist to detect this drift early and describe it accurately. Not as pass/fail gates, but as graded assessments of what is misaligned and how severe it is, giving orchestrators and maintainers adaptation options. Consequently, governance becomes policy-driven rather than reactionary, and the governance criteria remain known and current by default; otherwise, it appears transparently as system drift.
Editorial reality
Editorial complexity does not disappear in radial architecture; instead, it becomes visible. Taxonomies, variants, localization, and regulatory constraints still exist. In commerce systems, taxonomy is often owned by content teams, sometimes shared with merchandising or catalog teams. Radial architecture does not relocate that responsibility.
What changes is how editorial intent enters the system. Instead of being interpreted repeatedly across code paths, feature flags, and runtime conditionals, editorial intent arrives as a structured contribution governed by contracts.
For the sake of clarity, case studies may appear to hardcode taxonomy or page types. That is a narrative simplification, not a prescription. In real systems, taxonomy is often another CMS output, and radial pipelines accommodate that naturally.
Governance as architecture, not oversight
Radial architecture treats governance as part of the system, not an external influence on it. Policies are expressed as contracts, and enforcement occurs through validation. Visibility comes from evals; adaptation is handled by orchestration; and humans remain in the loop, but they are no longer required to manually hold the system together.
This is leadership leverage, not marginalization. When governance is structural, teams can move faster without fear because boundaries are enforced mechanically. Executives can assess risk and ROI without decoding tooling sprawl. Architects can evolve systems without relying on heroics.
Team alignment and workflow
One source of friction in modern systems is workflow. While our architectures have become distributed and modular, our workflows often remain linear. Even in organizations that embrace frameworks like team topologies, where teams align with system domains rather than aligning system domains with operations teams, work still flows as a stream through one domain to another until it eventually deploys to production.
While organizing around system domains has clear advantages, and those teams thrive, having been trusted with responsibility for their domains and the domain output, domain contact points remain entirely within the workflow. Design is still hands-off to engineering, and engineering still waits for APIs. Work moves forward by passing through gates rather than converging on outcomes because, although teams are correctly aligned, the system does not treat workflow as a system property.
This linear motion made sense when systems themselves were linear, but in distributed systems, and especially in AI-integrated systems, the work does not actually flow in a straight line; it converges on a central point.
Radial architecture aligns workflow with that reality. Instead of asking teams to sequence their work in time, it allows them to publish their intent in parallel within their own domains and for the system to resolve alignment at the hub. UX defines interaction capability, content defines composition, and so forth. None of these teams needs to “finish first,” they only need to honor their contracts.
The result is a fundamental shift in which work advances because it is structurally compatible with the rest of the system, even as the system waits to consume it as other domains contribute to future realignment. Of course, reviews still happen, but they occur under contract. Coordination still exists, but it is explicit and inspectable. Teams remain autonomous, but autonomy is no longer synonymous with isolation.
Most importantly, alignment is no longer enforced socially. When a content team introduces a new composition, the system can immediately assess whether UX supports it. When UX ships a new module, evals can surface where it is unused or misaligned. The hub becomes the place where all of this resolves because the architecture demands convergence.
Debt as a structural signal
Technical debt, design debt, and editorial debt are often discussed as failures of discipline or prioritization. In practice, they are usually symptoms of deeper issues, such as misalignment between how work is organized and how the system actually resolves outcomes.
In linear workflows, debt mainly accumulates silently. Design debt shows up when components drift from intent, and content debt emerges when taxonomies outgrow the assumptions baked into code. Technical debt appears when abstractions harden around yesterday’s decisions or a rush to deliver results in test gaps or shortcuts. None of this is inherently negligent; it is the natural byproduct of work moving forward without a place for convergence or governing blueprints.
Radial architecture does not eliminate debt, but it changes how and when it appears. Because domains publish intent through blueprints, misalignment becomes visible early and explicitly. A UX module that no longer fits emerging compositions, a content structure that exceeds available interaction capability, or a pipeline step that has become overly brittle all surface as structural signals, not latent defects.
This reframes debt as something the system can reason about, not something teams discover or incur under pressure. Design debt is a mismatch between declared capability and desired composition; content debt is an evolution in editorial intent that exceeds current contracts; and technical debt is an outdated constraint that prevents pipelines from adapting. Each is observable, attributable, and actionable.
Most importantly, debt no longer hinders, hobbles, or blocks progress by default. Domains can continue moving forward while the system records, grades, and adapts around known gaps. The cost of misalignment is paid consciously, with awareness and policy, rather than invisibly through friction and delay.
In this way, debt stops being a time sink or legacy gap and becomes part of the system’s ongoing negotiation with change. The architecture is not static; it exists as much in time as in a block diagram, and over time, it demands honesty by building assessments into blueprints. Coupling change over time as a core architectural principle enables organizations to move faster without losing control.
Governance, in this model, is something the system does for the teams rather than something teams do to the system. By declaring intent, enforcing convergence, and observing drift where it actually matters, radial architecture turns governance from a periodic intervention into a continuous property of the system itself.
Epilogue. First to market
If radial architecture seems vast and diverse, it really isn’t. The good news, especially for the enterprise, is that the existing distributed architecture is where you start. There’s no need to abandon years of development, infrastructure, and workflow. Clean up the boundaries, pay down some debt, and look to AI as a tool that ensures convergence without build-time integration.
Radial architecture gives us the patterns to move beyond the status quo without replacing it. The shift is from domain-driven design to boundary-driven governance, but only because we got the domains right. Now, it’s time to fill in the gaps between the domains, which is especially suited to AI agents and strict rules of contracts canonized in domain blueprints.
As autonomy enters the gaps between our artificial lines, architecture’s job is no longer to define what belongs where, but to govern how work, authority, and decision-making move across boundaries. Radial architecture exists to make those interactions legible, constrained, and trustworthy at scale.
So where do you start? It’s not an all-or-nothing proposition. While radial architecture aims to address the entire system, it’s more about mindset and tailoring what it offers to your needs. For some organizations, it means pipelines and agent autonomy. For others, it may mean evals and agent determinism. For everyone, however, it means opening the door to real, production-ready AI agent patterns and transcending pilots and prototypes to achieve production value and accelerated workflows that enable greater agility, especially in rapidly changing markets.
None of these ideas is specific to commerce. They apply wherever agents seek to add value, which means any system, even those that are not inherently distributed domains. Pipelines and their substrates, evals, etc., work on a small scale just as well as on an enterprise scale. You don’t have to have global operations to apply the principles of contract-driven accountability and system predictability.
For leaders and executives, the product or service vision becomes more certain as hidden coordination costs are reduced or eliminated by resolving intent with authority rather than through a complex web of integration and cross-domain alignment. Teams remain domain-aligned and autonomous within their boundaries, but outcomes converge structurally, governed by well-defined system rules and constraints.
The result is a system that scales by curating an ecosystem where AI can thrive as the force multiplier that it can be, and the ideas are endless. Think of pipelines as connectors to anything that has a blueprint and access. Ideally, MCP servers enable AI worker agents, but they are not a limiting factor.
As systems grow more autonomous, architecture’s role shifts from enforcing order to governing movement. When the system paths are explicit, AI becomes a collaborator, and scale becomes a property of the system rather than a burden on the people operating it. The future belongs not to the fastest pipelines or most intelligent agents, but to the architectures that can hold them together and accountable without losing trust. The AI hype is real, but only to the degree we want it to be, and only to the level we’re willing to build it.